

More about... High Resolution Inventory Solutions
HRIS Discovery Sprint
Tesera recommends an HRIS Discovery Sprint, as an innovative process to scope a potential forest inventory solution. It identifies the user's business needs, scope, objectives and requirements. Tesera collaborates with the Client to determine the requirements for the Sprint and prepares a draft Statement of Work for their review and approval.
Fixed Radius Ground Plots
HRIS applies a combination of Systematic Random Sampling and Strata Based Sampling. The number of ground plots required for a HRIS project is a function of the forest inventory attributes requested by the Client (as well as the precision of the classes within each attribute, and the accuracy of the attribute values).
Tesera can provide specific metrics on how different variable vs. fixed radius ground plot sampling strategies affect the inventory results. Individual tree measurements are compiled as target attributes at the plot area level.
Variable Radius plots are not typically used in an HRIS inventory, since the individual tree measurements are not spatially georeferenced. The lack of geolocation for the measured trees represents a significant limitation of Variable Radius ground plots. Also, many more Variable Radius ground plots are required (as compared to Fixed Radius ground plots) to achieve the same statistical performance.
The ability to fuse sub-meter georeferenced Fixed Radius plots with LiDAR and other remote sensed multiband satellite imagery enables deeper analysis of a broader array of features, and significantly more attributes to be generated for each polygon. Our approach reliably automates the delineation of forest stand polygons, including land cover classification at an average size of 0.5 acres/polygon. HRIS provides more comprehensive and statistically verifiable attributes for each forest stand polygon.
Remote Sensing Data
HRIS is designed to use a range of remote sensing data, including airborne LiDAR and colour infrared imagery, with the option to use satellite imagery and radar/SAR (for larger area applications, where aerial data capture is not practical). HRIS can also accommodate terrain, climate and other ancillary data.
This landscape level measurement data is used in combination with ground plot data to improve the reliability of estimates for attributes and features at the microstand scale (e.g. tree species). Machine learning features are calculated at the ground plot area and gridcell area from this landscape level.
Microstands and Gridcells
An HRIS Inventory is presented at a microstand level.
Microstands delineate stand boundaries (that have internal homogeneity for stand stature, structure and composition) into small polygons, and typically range between 0.5 and 12 acres (0.2 and 5 hectares). Microstands reduce the boundary effects of stands associated with different land cover classes. HRIS microstands can be aggregated, using hard and soft constraints. Gridcell predicted target attributes are rolled-up to the microstand level.
The inventory analysis is done at the gridcell level.
A gridcell is a sub-segment of a microstand, having a similar size to the ground plot area (to ensure a common aerial unit of analysis). Gridcells are the aerial unit of analysis in the HRIS inventory, and are designed to align with the ground plot data spatial footprint. Gridcells begin as approximately 65 feet x 65 feet (20m x 20m; or 400 square meters) spatial sampling grids across the project area. The gridcell boundaries are then split to conform to microstand boundaries. Targeted attributes are predicted at the gridcell level.

Microstands (blue) and Gridcells (grey)
Machine Learning
HRIS utilizes Machine Learning to model the relationships between attributes and the features derived from LiDAR and Colour Infrared Imagery (at the ground plot level), and then to predict those attributes at the gridcell level. HRIS data transformations (including normalization and scaling) are also applied to make the dataset ready for our machine learning models.
Our analytics and machine learning techniques include k-nearest neighbour, linear regression, random forest, support vector machine, neural networks and XG boost.
The image (below) depicts the application of our machine learning models to present clusters of various types of vegetation, based on their captured spatial and LiDAR features.
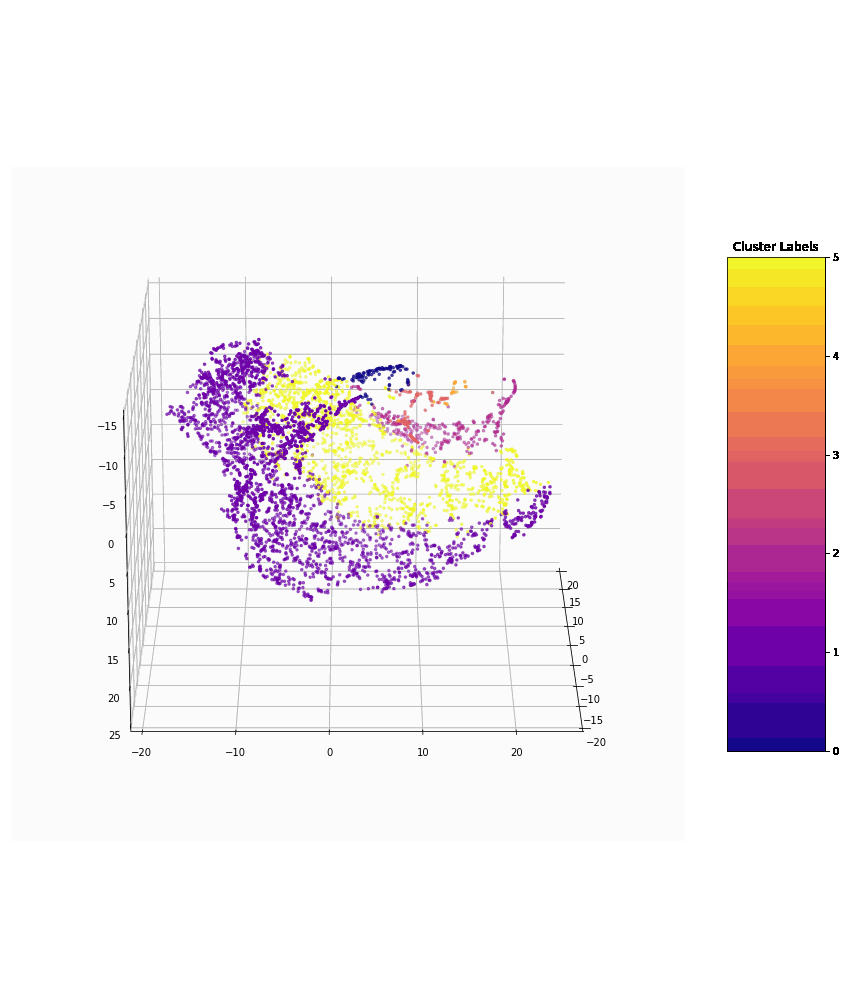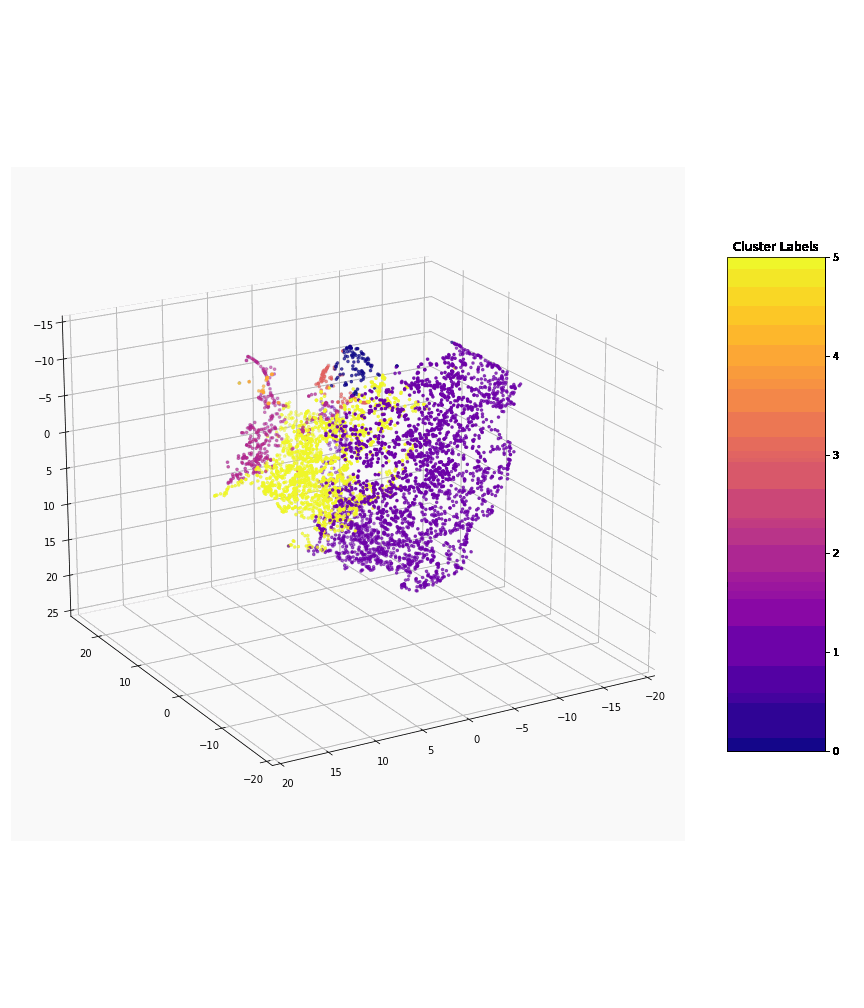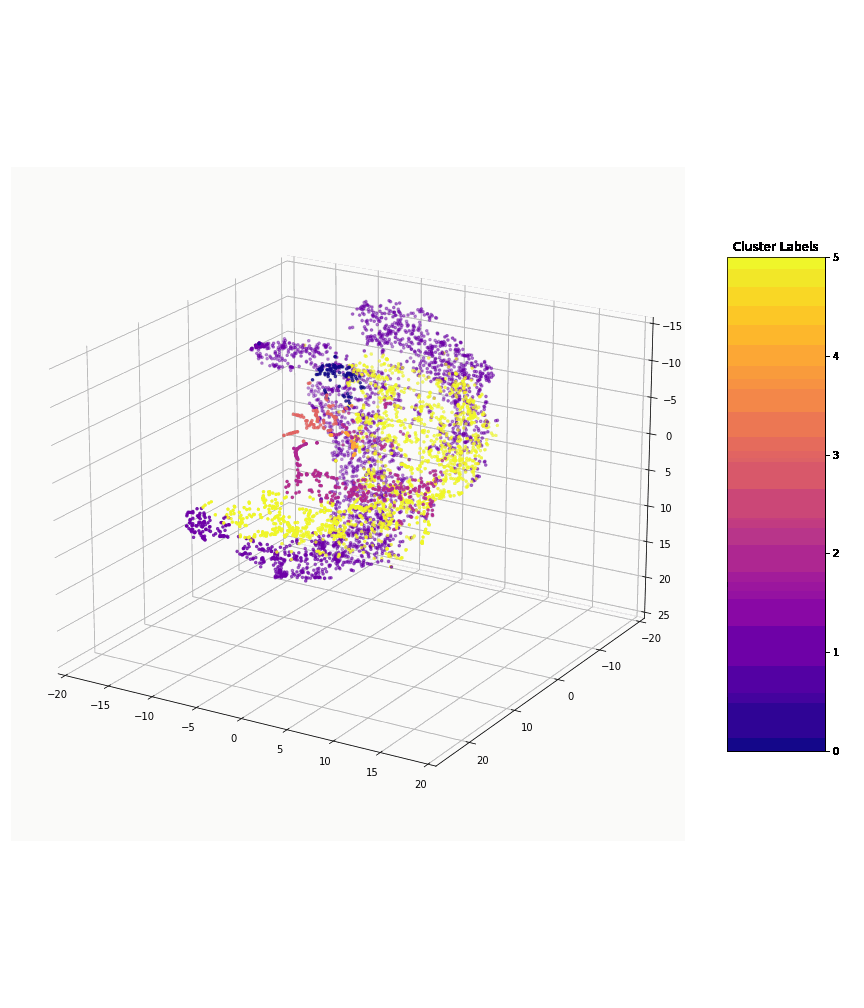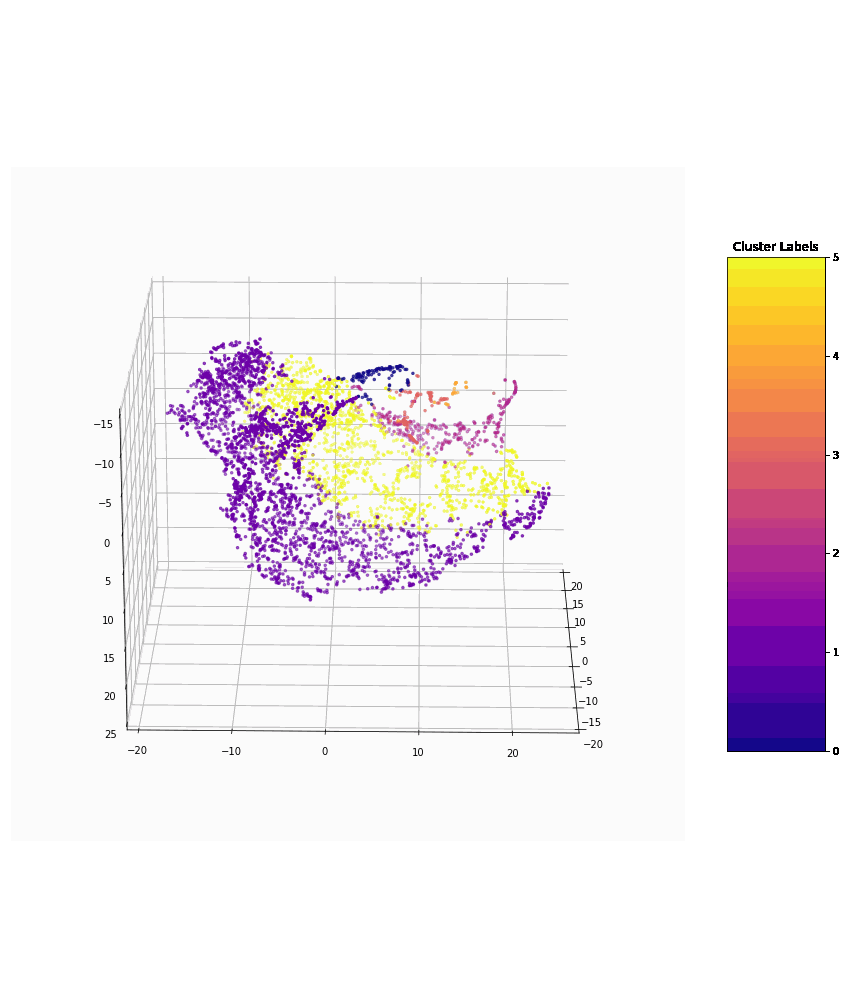
Clusters of various types of vegetation
The HRIS Framework
All HRIS inventories and data products can be visualized and analyzed using any standard GIS-based forestry system. The following outlines the inputs, processes and outputs for developing an HRIS Inventory.


Inputs
Tesera provides the specifications for the acquisition, timing, geolocation and compilation of these inputs.
Compiled ground sample plot data
Classified LiDAR point cloud
Orthorectified aerial imagery, DSM-orthomosaic tiled imagery, True (DTM) orthomosaic tiled imagery
Disturbance polygons, land cover polygons, land use polygons, roads polylines and polygons

Process
Acquisition of base data
Processing of sample ground plots and feature data
Selection of features
Machine Learning
Area segmentation
Processing and segmentation of feature data
Prediction of attributes
Compilation of the HRIS Inventory

Outputs
HRIS Inventory geospatial data and forest attributes (in any standard Client specified GIS format)
Optional data products: Predicted streams & wet area polygons, Contour polylines, Aspect rasters (slope and direction), Digital terrain and surface model rasters, Canopy height model rasters, Hillshade rasters, Individual tree crown polygons, Colourized infrared rasters, among many others…
Technology Stack
Data Storage / Processing
Our raw data and large raster and point cloud data storage utilizes Amazon Web Services (AWS) with Simple Storage Service (S3).
Our data processing development utilizes Python and R, with Git and Github as our code repository. We compile all of our code to Docker images, so that they can be universally used in any of our process environments.
Data and Machine Learning
Data derived through our processing tasks is stored in AWS RDS (Relational Database Service) in PostgreSQL, or in AWS S3 (depending on its subsequent purpose).
Our Machine Learning models are running on AWS Sagemaker instances, so that we can prepare, build, train and deploy our models. We utilize analytical techniques with Pandas data profiling packages, AWS Sagemaker Data Wrangler. Our feature selection (or elimination) is based on statistical algorithms including chi-square test, pearson coefficient, recursive feature elimination etc.
Data Processing
We have developed an advanced methodology that tiles our large datasets into small manageable pieces that can be easily processed as small tasks.
Data processing uses AWS Elastic Container Service, backed by EC2 Spot Instances. Our HRIS Runner, taking advantage of AWS Simple Queue Service, manages the individual tasks.
ML and HRIS Outputs
The training of our models is based on the nature of the problem. We leverage machine learning algorithms like k-nearest neighbour, linear regression, random forest, support vector machine, neural networks/ deep neural networks and XG boost.
The resulting HRIS Inventory is stored in geospatial format in PostgreSQL, where it can be accessed by the HRIS Map Viewer, or can be queried through an API, or exported to other geospatial formats (or applications) for the client.